Data Legibility and a Common Language
Data Legibility and a Common Language
Pt 2 of 3 | Pt 1: Social Infrastructure | Pt 2: New Public Amenities (coming soon)

Data needs to be legible so that more people can describe their opinions about technology, offer more genuine consent, and democratically shape the effects of data and connectivity. Civil society needs to champion data legibility to prevent existing inequalities from further deepening, and to decentralise the power vested in the existing creators of data and technology.
A common language may not traditionally be thought of as a component of social infrastructure, but without one, how can communities know what their assets are, what they need help with, and what they want to change? The first step to a common language is making data legible. Once data is legible, humans can and will co-create ways to talk about it.
Why data should be legible
Whether or not you have a Facebook profile, Facebook has a profile about you. Whether or not your phone is turned on, your “local smart city provider” knows where you are.
We are still “data subjects” (as the GDPR would have it) even if our digital skills and connectivity are poor to non-existent. Our health records, credit scores, the price we pay for goods, our access to government services and many more aspects of modern life are all mediated by data and connectivity.
It is not realistic or just to expect that everyone can and will be educated to negotiate the increasing obfuscation and ubiquity of data; technology needs to meet us at least half way. Just as accessibility is now a legally mandated standard in the UK, data should be legible to everyone, and civil society needs to develop new competencies to help everyone to read it.
Data and connectivity are ubiquitous, invisible, and overwhelming. It’s worth remembering that the word “data” was originally a plural, as in: there are too many data, they are too hard to see, and their consequences are too difficult to contextualise. Data are not legible in the real world and — unlike other great unexplained phenomena — there are no myths and legends that make sense of them.
Data is not, therefore, simply a commodity like oil, it is also a power relationship.
Bodies that can understand and exploit data have a power over those who do the hard work to create it. As artist James Bridle says:
Those who cannot perceive the network cannot act effectively within it, and are powerless.
Data could exist within democratic constructs, but that currently feels too big, too untameable to be achieved. This is in part because we don’t know how to talk about it. There’s a lack of meaningful public discourse about data and connectivity because we simply don’t have the words.
Because it’s difficult to talk about things we can’t see, society’s attention is often rerouted to the negative symptoms of data, rather than their root causes. Symptoms like the Cambridge Analytica scandal, the failure of facial recognition in policing, teenagers’ need for positive social reinforcement on Instagram, and fake Peppa Pig videos are all simultaneously shocking — but not actually that surprising. They are inevitable in a world where, to quote the title of a recent Supra Systems Studio exhibition, “Everything happens so much”.
In his Course in General Linguistics, semiotician Ferdinand de Saussure describes language as “a heritage of the preceding period.” Current reality often has to make do with the language of a previous generation; we have no words for the thickness and intensity of our data experience because it is being newly formed around us every day. So we need to wrestle this heritage language into a serviceable shape in order that more people can describe what they perceive, and others can recognise the signs to spot. Our lived-experience is co-created by our articulation of it, and as Saussure goes on to say, “Without language, thought is a vague, uncharted nebula.” Without language, data and its effects are vague, uncharted nebulae too.
Do we need a data consciousness?
In her novel Outline, Rachel Cusk describes the imaginative world that brings together two small boys in play and discovery:
much of what was beautiful in their lives was the result of a shared vision of things that strictly speaking could not have been said to exist.
Humans make sense of the world through an ongoing process of approximation. We bring together our empirical selves — our beliefs and feelings, those things that strictly speaking could not be said to exist — with the things we can rationally understand.
Usually, we do this together — by telling stories, sharing faith, finding communities, appreciating art, laughing at jokes. We make sense collectively by rooting ourselves amid others or creating one-to-one connections. But smart phones change that. We are infinitely connected but physically alone. This lack of physical connection changes both our accountability and our ability to pick up cues: no matter how often it’s said, the same rules don’t apply online as off. The ability for misunderstanding one another in written online communication is unparalleled in face-to-face communication. We are rootless, alone, swimming in data that we can’t see, magnified in our self-righteousness.
So how can we better situate ourselves?
Timo Arnall’s photography and film-making visualise how data is at work in the real world and brings to life what it would look like if it were decoupled from a screen or a spreadsheet. But to have the power to imagine this, one needs to be able to acknowledge that the data is there. And if that were possible, what would become of human existence? Rather than getting on with the messy complexity of living, we’d be fully occupied spotting the trails that data leaves behind and requesting explanation from incomprehensible algorithms. There is, of course, much more to life than this.
So, if there is just too much data, can it ever be cognitively accessible?
As neuroscientist Anil Seth writes in “The Hard Problem of Consciousness”, “Every conscious experience requires a very large reduction of uncertainty.” This is what we do as humans: we make sense of complexity all of the time. Many things are too plentiful and difficult to understand, but we continue to navigate them all the same. Not every level of comprehension needs to be granular and formed from the bottom up.
Shared mental models, symbols and vocabulary help us to fix meaning and reduce abstraction. We all agree that an animal that barks and has four legs and a wet nose is a dog. I may not know what kind of dog I’m looking at, but I understand the concept of dogs, and can recognise this one as being big or small, old or young. I don’t need to understand the idea of dogs every time I see one, or research and create my own idea of what a dog may be. There is a culturally available definition of “dog” that I agree with and can use.
But this is not the case with data. For most people, most of the time, data is invisible, infinite, intangible. To describe it, I’d need to obtain it. To obtain it, I’d need to know what I was looking for.
Similarly, everyday human experience is not spent decomposing people or objects into their constituent atoms. While most people can acknowledge that something called an atom exists, we don’t need to recognise atoms to understand the things they constitute.
So, of course, physics is a vital part of modern life, but it is completely acceptable that most human sense-making does not happen at an atomic level; it happens at the level of recognising a dog, a feeling, or a face. We group atoms until they are visible and recognisable as people and things. For most people, most of the time, it is not possible to do that with data.
Obviously a data scientist or an analyst has a different view — and this is one of the reasons we’re at such a societal impasse with data literacy. The conceptual frameworks that inform how data moves through society are expert, logical and at atomic scale. There is a language for expert consideration, but not one for everyday communication.
Confidence is not the same as consciousness
During the focus groups for Doteveryone’s People, Power, Technology research, we asked people to mark themselves out of 10 to show how good they were at using the Internet. Very few people gave themselves less than a 5, and nearly everyone was over a 7. There were quite a few 10s out of 10.
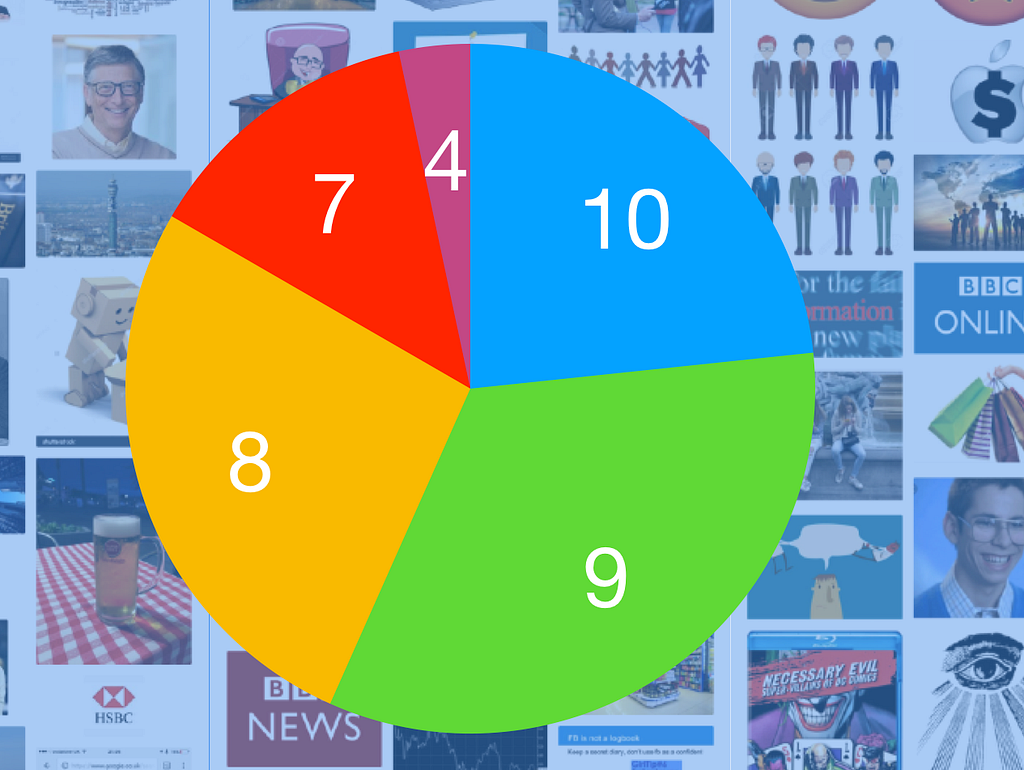
And as we discussed the rating, we realised the feeling people were describing wasn’t their ability or their understanding, it was their level of confidence. Confidence that they could use the service, that it would work first time. In fact, it was often confidence in the ability of the service to work, not in the individuals’ ability to navigate it. Most people don’t know how their Uber turns up at the exact place they’re standing, how Facebook knows who they want to connect with, or how their Netflix recommendations work — but they know they can rely on that service, and they know they can use it, so they feel confidence in it and have an illusory feeling of being in charge.
And this feeling is very illusory. Things that are easy to use and hard to understand depend on sleight of hand to work: we are cheerfully skating on thin ice, until the ice breaks. We are not “acting effectively”; we are just lucky.
Designer Richard Pope argues that “accountability needs to be embraced as part of the service design” of frictionless digital products, but even this strikes me as too plural. I already work hard enough on behalf of my data — so hard, in fact, that this work is now captured as part of “Household Labour” by the Office of National Statistics — and I certainly don’t have the free time to listen to algorithms explain inexplicable things to me.
I cannot manage a hundred different mental models for a hundred different services; I want an extensible conceptual understanding of How Data Works that I can port from service to service. I want the services I use to meet my mental models, rather than for me to do the hard work of understanding how a dozen different paradigms function.
And I also want to know if it is palatable to me or to people I know that the NHS is going to use a “digitised system” to verify whether I need to pay for prescriptions; that my neighbourhood is going to become a test bed for self-driving cars; that I pay less for my car insurance than someone called Mohammed; that the show I’m currently bingeing on has been algorithmically optimised to keep me watching. I want to be a functioning data citizen who can make meaningful choices.
And I cannot make an effective choice if I can’t explain what I have chosen.
Human-readable data
In his book Misbehaving, Richard Thaler — one of the originators of behavioural economics — explains that most economic models don’t work in the real world because “the model used by economists … replaces homo sapiens with homo economicus”. In other words, economics doesn’t allow people to act like the contextual, spontaneous, often irrational beings we are, pulled in a hundred different directions by real life. We’re expected to behave logically within a single track.
As Prof. Safiya Noble has shown in Algorithms of Oppression, there is a disconnect between real life and the “information reality” that is presented by many products and service. This is in part because the reality shown reflects the limited reality and partial opinions of the (often white, often male, often Ivy League educated) people who made them; there’s no information omniscience, no higher truth hidden in the data, it’s simply an artefact of a certain set of privileges and biases. Noble says that:
Commercial search, in the case of Google, is not simply a harmless portal or gateway; it is in fact a creation or expression of commercial processes that are deeply rooted in social and historical production and organization processes.
So to understand my Google data, I have to understand them in these contexts. They do not represent my truth, but Google’s truth.
On top of this, database architecture, software engineering and data science are fundamentally still logical disciplines. Like Thaler’s economists, the uncertainty of human life is trusted to people for whom uncertainty is often a failure. For instance The Telegraph recently published a story about an Amazon Alexa patent that describes the perfectly normal human reaction of crying as an “emotional abnormality”; this is the Spock Problem from Star Trek writ large, except that it needs much, much more than a single heroic (white, male) Captain James T. Kirk to balance it out.
Data should be a social artefact that can be interpreted and debated, not simply a perspective masquerading as fact. The lack of an accessible language or relatable set of concepts places data and connectivity out of reach of both public and multi-disciplinary discourse. Without a common language or a shared consciousness, data will carry on being used to construct the partial “information reality” that Safiya Noble describes. But with a common language data stands a chance of becoming more available as a material to different kinds of inventors, educators, and commentators. Greater legibility will give data lives outside of the logical prism of data analysis and and start to decentralise the power and authority vested in it.
To be a truly humanly useful material, data needs more ways in. It needs edges and seems and gaps.
Can I describe it?
Prof. Anne Galloway’s paper, “Seams and Scars, Or How to Locate Accountability in Collaborative Work” discusses the potential of seamful technology. Rather than allowing “new technologies to fade into the background of our everyday lives”, Galloway offers up transitions— “liminal spaces” — as tangible entry points for understanding:
In cultural terms, liminal spaces tend to be navigated by ritual. For example, weddings mark the transition between single life and married life, funerals mark the transition from life to death, and both mark passages and processes that shape individual and collective identities.
In other words, in real life, we celebrate the very bumps and lumps that get minimised in our digital experiences. Galloway goes on:
So liminal spaces are spaces of potential or becoming; they are places where things change and interesting things happen. As such, I find remarkable hope in seams and scars.
So what is the potential of seams and scars?
A seam is a useful cognitive prop for making data legible. The act of showing how two things come together, or how something has changed, is an opportunity for to create a describable moment amid a mass of otherwise inexplicable interactions. Creating a visible seam makes it possible to describe a transition rather than explaining a whole data reality.
But describing every single thing that changes in our data landscape, all of the time, is still too big a cognitive load for even a not-very busy human.
So what is the appropriate level of seam that will make data legible enough?
Can I consent to it?
Seams should reflect changes in the situation human, not in the situation of the data. Making data legible in the context of human experience makes it much easier to understand.
CityMapper is already pretty good at this:
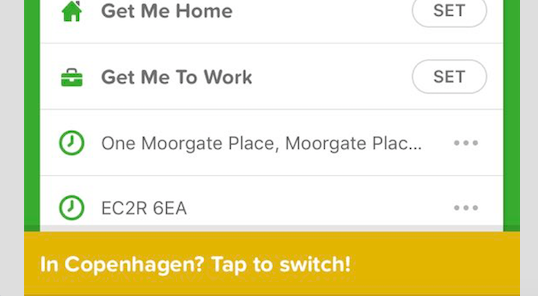
This notification makes it clear that the app recognises I am in a different city to the one I am searching for directions in. Rather than seamlessly relocating me to where it thinks I am, it asks me to change my location—offering an incidental reminder that it knows where I am right now. This is useful and reinforcing, requires a fractional amount of labour, and is a building block for a figurative understanding of location data. I can discuss this because I can see it. I can say, “CityMapper knows I’m in Copenhagen!”, rather than “CityMapper’s only letting me search locations in Copenhagen, but I want to know how to get to my meeting in London tomorrow!”, while also scrabbling around in Settings to make it work and cursing who-knows-what on my phone for several minutes before giving up and using Google Maps and still being none the wiser. It is simple, useful, and legible.
This kind of seam recognises that consent is an ongoing aspect of a relationship. It understands that my consent changes as I change, and that I can also choose not to comply with the prompt. All kinds of things can happen in the seams.
Projects by IF have pioneered setting out design patterns to create this kind of legibility. Their Data Permissions Catalogue sets out exemplary paths for common interactions that make data more legible. It is unrealistic to ever posit that all (or even a substantial number of) services will ever use the same design patterns, but just as the W3C mandates Accessibility standards, there should be global standards for data legibility that civil society is equipped to support, champion, and campaign for.
This is not a case of giving people skills; there is no point in being given the skills to understand a thing that few people can see or understand. It is a case of making data visible so that anyone can see it, comprehend it on their own terms, and ask for help and support when they need it.
As automation continues apace, and data and algorithmic processes reach true ubiquity, legibility will become a human right. Society should care much less about teaching people to code, but concentrate on creating the conditions for more of us to cope.
Data Legibility and a Common Language: Coping Not Coding, part 2 was originally published in Doteveryone on Medium, where people are continuing the conversation by highlighting and responding to this story.